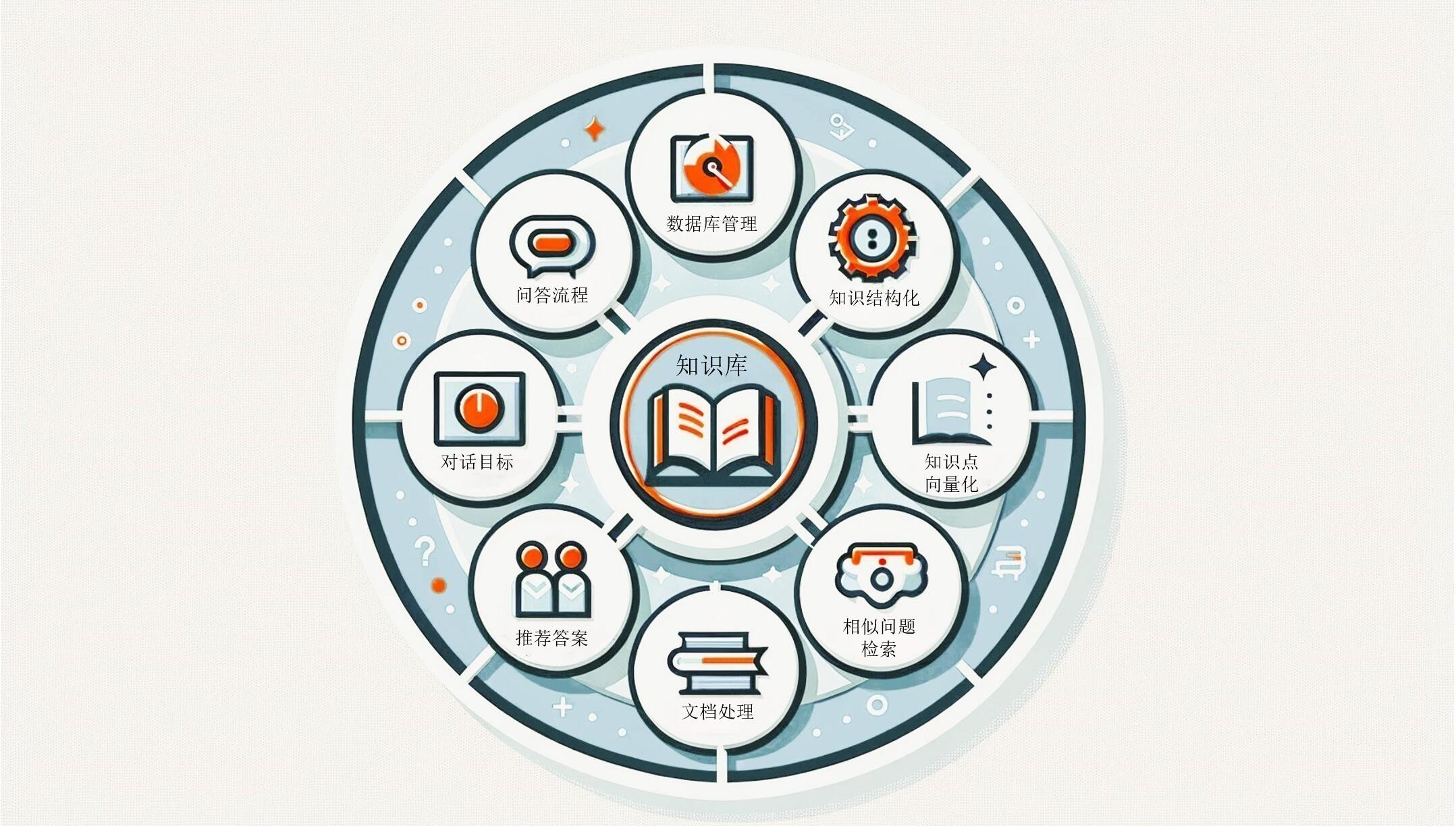
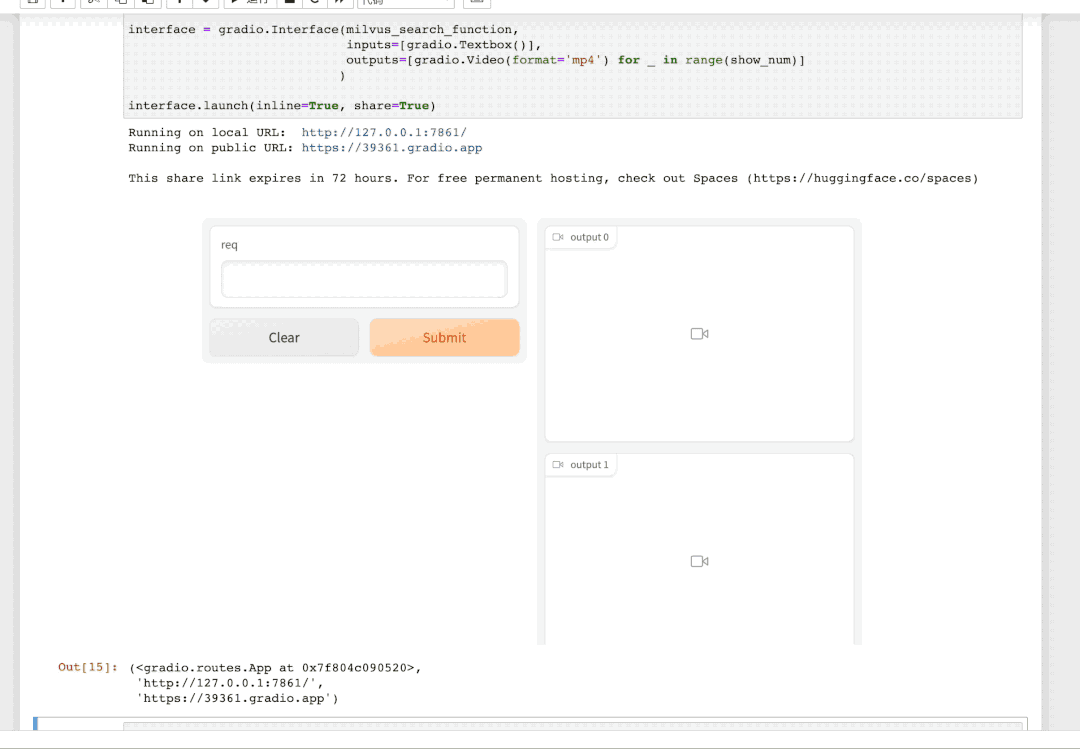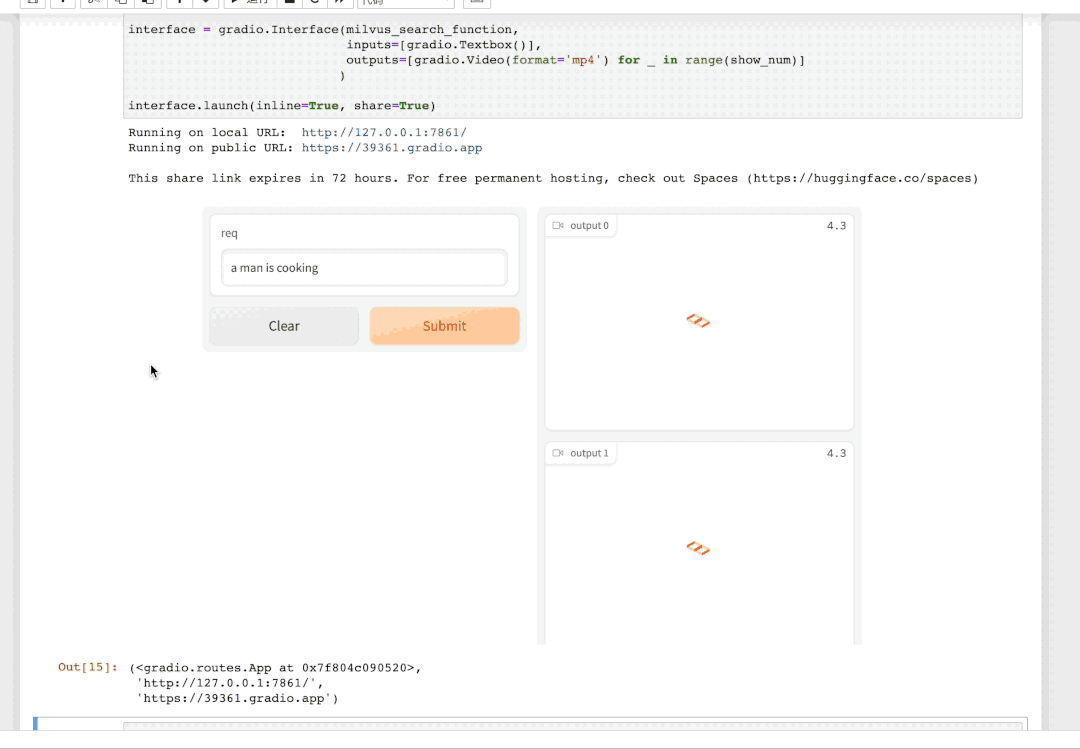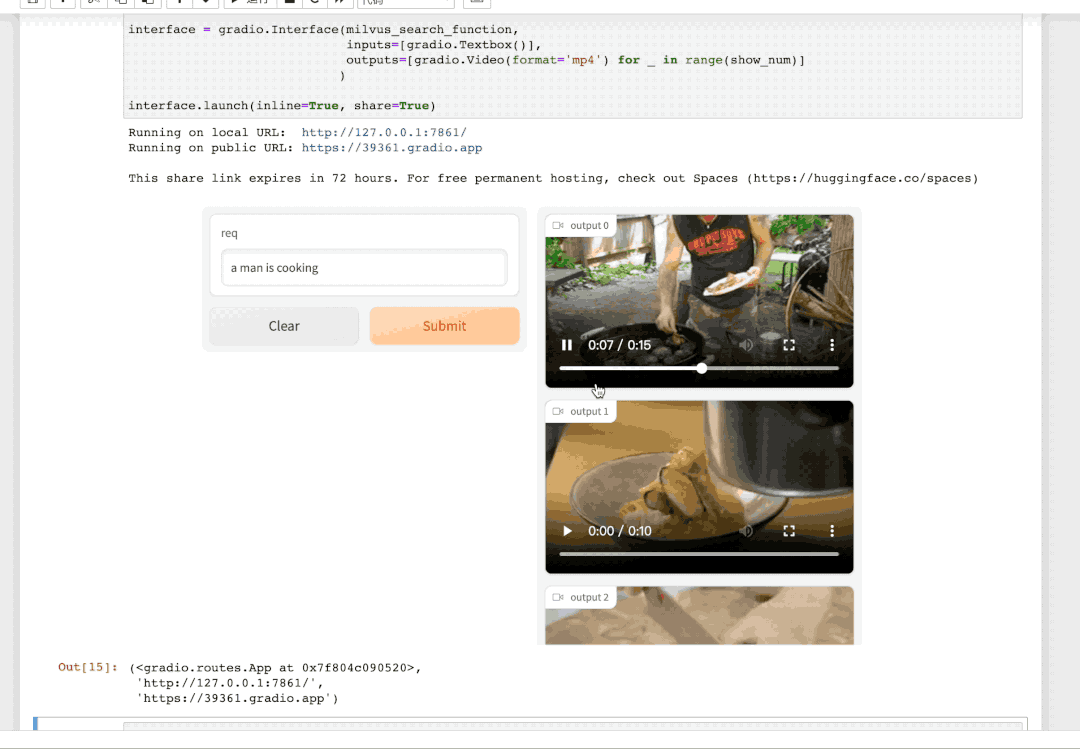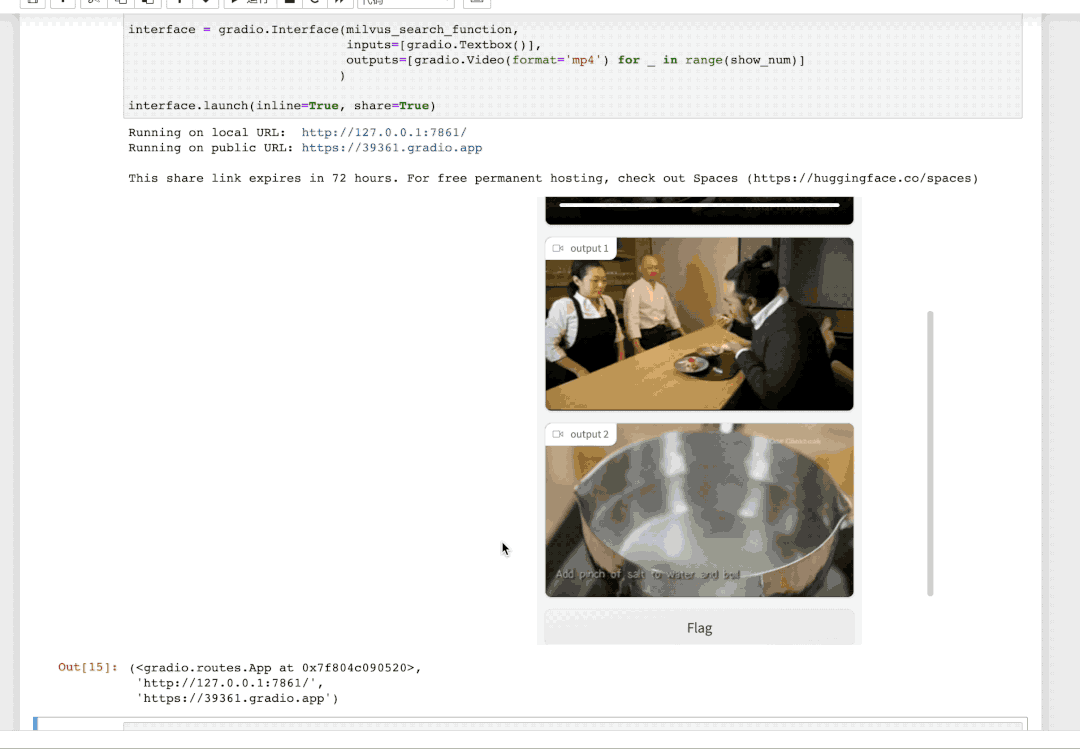
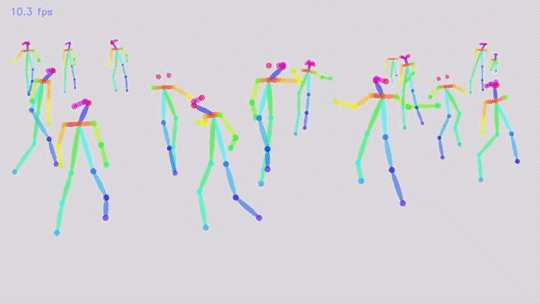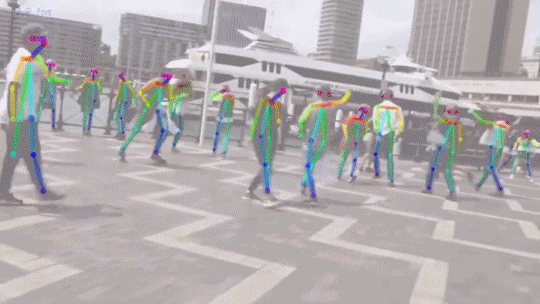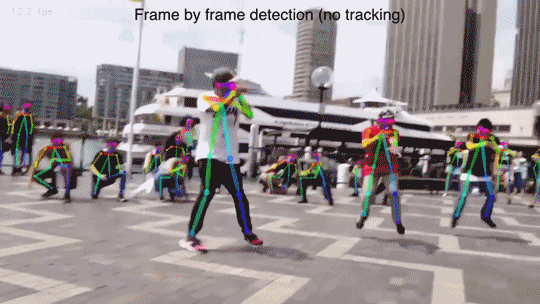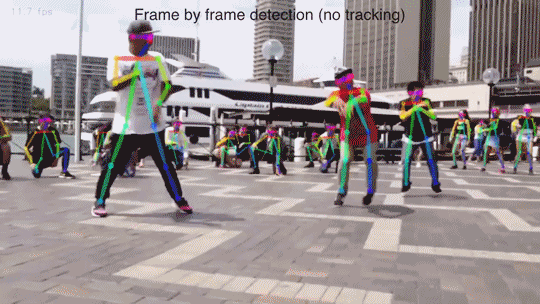多媒体知识库主要任务是维护知识库,再结合大模型实现准确的知识获取、理解、分析、总结,最终以文本、图像或视频的形式,为用户提供相应的知识或决策。...
可控多媒体内容生成是指根据多种模态(如语音,文字,图像)的参考条件来引导生成一致性的目标内容。例如:电影游戏的场景和动画角色设计,个性化的图像和产品设计、虚拟主播,元宇宙,电影游戏中角色动画、虚拟场景建设、特效设计等。...
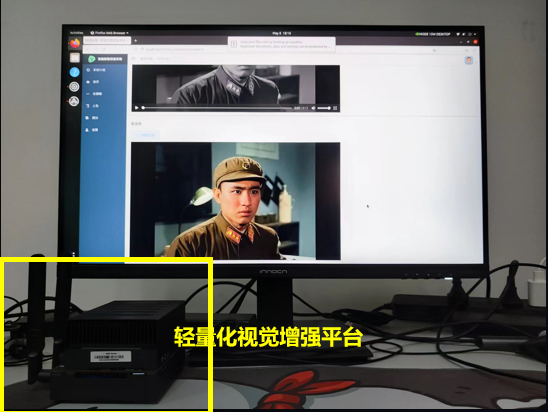
视觉增强是一种通过使用不同的技术和算法来改善或增强图像的质量、清晰度或感知效果的过程。...
视频场景理解是指通过分析视频数据,以获取对视频中所呈现的环境、物体、人物和其它元素的深入理解的过程。...
将基于用户兴趣和观看历史来实现个性化视频推荐。通过在边缘设备上分析用户的观看行为和反馈,可以实现更加即时和个性化的视频内容推荐服务。...
神经网络模型在实际场景落地时,需要经过优化以保障模型的正确和高效的运行。正确运行需要提升模型的鲁棒性,降低用户攻击模型的可能;高效的运行依赖于模型的轻量化和并行,降低模型运行所需资源并提高整体系统的吞吐量。...
从图像和视频中定位目标所在位置、范围及类别的技术。...
通过计算机视觉算法对视频中“人体”的姿态(关键点,比如头,左手,右脚等)的位置估计,跟踪与重建...
通过计算机视觉算法对一个或多个摄像头产生的视频流中的行为信息自动进行分析和理解...